Dynamic Configuration System
Index
[TOC]
Overview
People all like generic software solutions, but as the scale of modern computer system grows larger, there are business logic cannot be avoided in order to handle real world complexity, Tax Rules, Accounting Treatment, Pricing/Deal calculation…
However, write business logic in code was never recommended because it will result in
- Hard-to-read code: code are not readable without huge documentation
- Hard-to-test code: code will be tested against specific business and not able to test generically
- Hard-to-change code: change won’t be in effective until code deploy and also hard to revert
- Hard-to-analyze data being processed: metrics can not be easily emitted and analyzed
Here is where a dynamic configuration system (short for DCS) comes into play and we will see how it solves all these problems.
Definition
A DCS abstracts business logics layer from other layer in a readable and testable fashion during runtime, it should generally allow store, edit, update configuration as well as fetch them by certain conditions.
To put it simple, a client of a DCS should be able to
- PutConfig: upload configurations containing business logics
- GetConfig: fetch configuration by filters
- ProcessConfig: given inputs, DCS should match against stored config and produce results
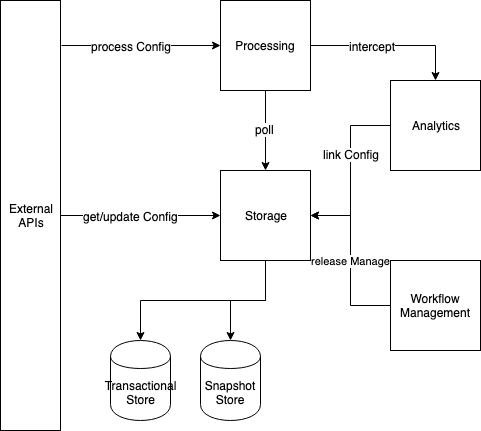
Modeling
Model of a configuration is tightly coupled with its functionality. Here we will only cover the essential functionality of the DCS where new result should be produce by given input and configuration.
e.g. input:
1 2 3 4 | |
and config:
1
| |
we should get:
1 2 3 | |
as a response. (The above syntax is ion)
Then its not hard to infer the very basic piece of a configuration is a compose of condition and resulting value. (Lets call it a derivation config) A naive model can look like this:
1 2 3 4 5 6 7 8 | |
and of course a group of derivation config can be written as:
1 2 3 4 5 6 7 8 9 10 11 12 | |
and multiple conditions are and relationship.
Storage
We have the model of derivation configuration now, but how can we store them? A traditional relational database and reference by id? or a document based storage reference by nature key? Let’s take a look at both of them.
Relational
| row_id | config_element_id | config_data |
|---|---|---|
| 1 | 1 | {conditions:{c_1, c_2}, value:{v_1}} |
| 2 | 2 | {conditions:{c_1,c_2}, value:{v_2}} |
| … | … | … |
Benefit of this approach is:
- Strong consistency guarantee, much easier to work with in a multi-thread access environment
Downside of this approach is: (All come from the persistence identifier!!)
- Extra cost to maintain additional id. id is required to be present everywhere in the DCS, big waste of space!!
- Requires additional joins when querying, slow down the access speed!
- Huge pain when it comes to editing the configuration, id has to be carefully handled and matched. (Simple diff doesn’t work!)
- Duplicate check can be hard, even though 2 config data is duplicate, we still treat them as different if they have different
config_element_id
Despite all those negative thing with relational database and persistence identifier, we will still be using this approach in this article because this has been proven to work in production environment.
NoSql
| key | value |
|---|---|
| condition_1:cond_1/condition_2:cond_2/value_1 | v_1 |
| condition_1:cond_1/condition_2:cond_2/value_2 | v_2 |
| … | … |
Benefit of this approach are:
- Simpler data model, no separate persistence identifier resulting in faster query speed
Downside of this approach are:
- Hard to guarantee consistency (Especially in a distributed k-v store, manual distributed lock has to be implemented and maintained by DCS)
In-Memory
It’s expensive to always go back to database and retrieve information for every operation DCS needed. An in-memory representation of configuration is also needed.
The most nature way of storing key-value pair chain is Trie, and that’s what we are going to use:
1 2 3 4 5 6 7 8 9 | |
Is a representation of
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Ordering of conditions in tree are guaranteed by alphabetic order by default and is “configurable” for different tenant of DCS.
To formalize a little bit, a config tree node can be represent as (in haskell)
1 2 | |
S3, Caching and Interning
In-memory Tree are also not directly built from RDS database because it can take minutes or even ours to load few entire tree, instead, every latest changes are truncated to a snapshot, serialized & compressed to store in S3, 99% of the time, s3 are the storage used to fetch the configuration.
In-memory Tree in DCS are 1 tree per snapshot and that’s what DCS keeps in the cache as well. If an entire tree is 4GB, and a typical DCS host has 60GB, only 15 snapshot can be stored at maximum! Request will have a huge latency spike if there is a cache miss. Here comes the idea of interning.
Interning (like String interning) is a technique to share repetitive in-memory object by putting them in a poll. This saves the memory of cache because multiple snapshot shares the same piece of subtree. And DCS calculates repetitive solely based on its hash key.
Filtering and Indexing
One interesting thing about fetch configuration in DCS is filter. DCS supports filter that allow access configuration from different dimension. e.g. by config_element_id, by status…
This means different indexing of the configuration has to be built, there are global index for indexing config_element_id (unique), there are per snapshot index for content key to perform duplicate lookup…
Keep adding index is also not scalable and interning won’t help because different index will likely have very little to share. A DCS might consider using graph based DB to better help with indexing and querying tasks.
Collapsing Configuration
TODO
Tenant Separation
Muti-tenancy is an important consideration for DCS:
- Every config element and operation should be directly or indirectly associated with a tenant and they can be traced from the Database
- Request for DCS should always pass in tenant, and ownership shall validate & approve the request before any operation
- Tenant should be able to easily manage their tenant configuration (e.g. ownership)
Authoring
Authoring is the process of PutConfig into DCS. Enable parallel editing, bulk editing and consistency model will be the main focus of this section.
Why not using Git?
Git treat each line (or even character if you’d like) as the lowest granular editing, however our DCS treat a single config element change as the lowest granular editing. They are fundamentally different!! Using git means we cannot use “line changes” of git directly as “config element” changes which immediately brings no benefit of using git! Plus, change can be very hard to validate before pushing, traditional pull/rebase/code review/push model won’t work because DCS are changing so rapidly and concurrently!!
It then became very obvious that instead of hack Git and trying to put different pieces together, we are better off building our own authoring workflows.
Change List
Change list is a list of config elements that represents changes a person is trying to make in DCS.
| change_list_id | change_list_revision | config_element_ids |
|---|---|---|
| 1 | 1 | [1,2,3] |
| 1 | 2 | [4] |
| 2 | 1 | [5,6] |
Work Request
Work request act as a container for change list. A Work Request can have multiple change list but a Release can only have one work request. A typical WR contains 2 type of change list:
- 1 Active change list: track changes that has not been released (all updates are write to this change list)
- (0 ~ Many) Change Lists: all change list that has a release associated
Concurrent update to work request are guaranteed by optimistic locking mechanism. A work request update always require both change list id and change list revision, if an older revision of change list is being submitted to the database, it will get rejected.
Initially work request were designed to have no revision associated, but as time goes, it became more obvious that add revision to work request can provide better audit history of work request updates and potential work request snapshot for running reproducible tests.
Snapshot
Snapshot is an important concept in DCS as it provides a way to represent an immutable set of configurations. This enable audit history of all configuration changes and also point-in-time recovery (or reproduce of the transaction). There are 3 types of Snapshot:
- Latest Snapshot (aka Base Snapshot or Release Snapshot): track the latest snapshot of a given domain
- Config Update Snapshot: track a snapshot for change list
- Merge Snapshot: containing multiple snapshots and a resolver containing instruction on how to merge them
Release Process
An release process in DCS transform the latest state of DCS from 1 good snapshot to another. The soundness of change are guaranteed during the release process. A typical release workflow contains:
- Duplicate check
- Reference check
- Conflict check
- Run test
- Merge or Rebase
A DCS cannot be successful without a well defined & executed release process
Concurrent release
Config Update Snapshot -> Merge Snapshot -> Release Snapshot (Optimistic Locking)-> Latest Snapshot
concurrency were simply handled by an optimistic locking between building release snapshot and promote as latest snapshot. latest snapshot table are updated by providing domain, release snapshot and latest snapshot. No duplicate revision can be created and that’s guaranteed by database transactions which also guarantee the concurrent update to the DCS.
Rebase
There are a situation where 2 releases changing different config elements and trying to release at the same time, due to the fact that only 1 snapshot can be marked as live at given time, one of those 2 releases will always fail. However, there is a smarter way we can do to ensure both release success by rerun part of the release workflow (aka. Release process)
Whenever a release fail to be marked as succeeded, DCS will check the error type, if the type is OUT_OF_DATE_BASE_SNAPSHOT, which means there are other release succeeded before this release finishes, a rebase workflow can be kick off.
A rebase workflow essential bypass all the manual approval steps and only run the automated validation/testing steps and then trying to merge in again. However, it’s possible for an unlucky release (starving) to keep running rebase workflow and maybe never succeed.
In order to solve release starving problem, preemptive rebase mechanism was introduced, all the pending rebase release will be put in a queue and every release will pre-computes changes that needs rebase base on release ahead of them in the queue. (A new RebaseAttemp object and Preemptive Rebase Workflow is introduced and replaced old rebase workflow)
Partial release
partial release is the feature of release only a subset config within the work request. It was originally implemented using a concept of Release Unit, which can be created from path of the tree. A request of partial release will have normal release object plus a specific Release Unit and DCS will figure out what need to be released.
Release Unit soon became a pain because it creates additional layer between change list and release/work request, its both programmatically difficult to figure out relationship between release unit, release and work request and un-intuitive for end user to create a correct Release Unit.
Release Unit based partial release was then deprecated by partial release via raw tree where release request will contain a tree that explicitly describing what should be released.
Tree Operation
Merge
Merge is a multiple tree operator which can be applied to 2 or more trees. Tree Merger folds the tree one by one and it first creates a conflict tree out of merging trees and then use resolver to transform them back into a normal tree, resolver is required by Tree Merger and sample resolvers are:
- last_one_wins: just use the last node seen
- optimistic_locking: ensure right node (CE) must have larger revision than left node, otherwise merge will fail and this is the only resolver that might fail. This is also the default resolver used in release process.
- latest_revision: use the latest dated_released_config_revision
Conflict Resolution
Conflict happens all the time during release due to optimistic_locking resolver and simultaneously modification of the same config. Conflict Resolution mechanism provides a way for user to get the conflict tree in their release and select side of the tree, manually resolve the conflict and resume the release.
DCS did this by deleting conflicted configs and adding a new config back as user selected. However, this did introduced an interesting bug (and caused a COE). Because the way DCS are adding new configs instead of re-using existing ones to actually “resolve” the conflict, duplicate configs can easily be added. Someone actually took advantage of this bug and duplicated an entire namespace multiple times!!
This was later fixed by adding duplicate check across the platform but removing existing duplicate is very hard and still on going.
Diff
Diff is a dual tree operator which can only be applied to 2 trees. Tree Differ perform a transformation from 2 StandardTree to 1 DiffTree where each node is of type DiffNode and contains a left and right.
Diff tree can be transform to StandardTree again by traversal the tree and select left or right. In fact, config update snapshot should was produce by selection all right side of a Diff tree.
Testing
Test cases are in/out files that can be executed against certain snapshot, they are defined & authored the same way as other configuration in DCS but in a separate namespace.
Testing will be done in a custom test suit which will take care of getting test configuration, convert it to java test cases and then start a in-memory DCS (processing engine) to process test cases.
We faced few performance issue where test run are getting extensively slow after sometime. Since we know testing are CPU-intensive calculation, mostly the focus on optimization were done one CPU. However, it turns out with the increase in test case size, JVM is running out of heap. A lot of CPU cycle was wasted on busy GC. Simple increasing heap size improved the testing time to be 10x faster. (gceasy.io was the tool helped a lot)
Ownership
Too low granular to use.
Processing
I wrote a very basic haskell program demonstrating how processing against tree works. It basically has a main process function where it loop through each record then try to derive attributes/record. Newly derived record will be directly append to original record list (so the function is not pure and it relies on IonList implementation to work correctly)
Best Match
Execution Context
Namespace
Analytics
TODO
Future
DSL and DCS